Chapter 1 Introduction: Audiences, purposes, questions
Information technology has brought large volumes of data and the promise of a deeper understanding of a wide range of challenges from understanding the quarterly performance of a company to the effectiveness of a healthcare system or the health of an individual. Often this promise is not kept and data overwhelms rather than informs. Often a well-crafted visualization can address this problem and make data meaningful. This book provides principles and examples to make large volumes of data meaningful through visualization.
The book combines general visualization principles illustrated with examples. It also includes the computer code so that each graph can be reporduced and used to plot other data. Nearly all the examples use ggplot2 which makes it relatively easy to replicate some of the classic visualization suggestions of E. Tufte, such as his minimalitic graph styles, as well as slope graphs (Section 5.3.4) and small multiples (Section 4.9).
The book also includes ways of addressing common challenges with ggplot2, such as removing legend (Section 10.2.7) and reordering categories of column charts.
1.1 Seeing meaning rather than numbers
Figure 1.1 shows a typical report of a medical diagnostic test. The numerical summary shows the patient’s values and the range of standard values. The information is there to show if a patient is dangerously outside the range, but a quick glance at the table might miss these indications. Even a careful reading of the table might miss warning signs, particularly if the critical information is in the trend that requires looking at a second table on another tab. Figure 1.2 shows the data relative to the high and low normal range and makes deviations much more apparent. The ghosted points show past results and roughly indicate trends.
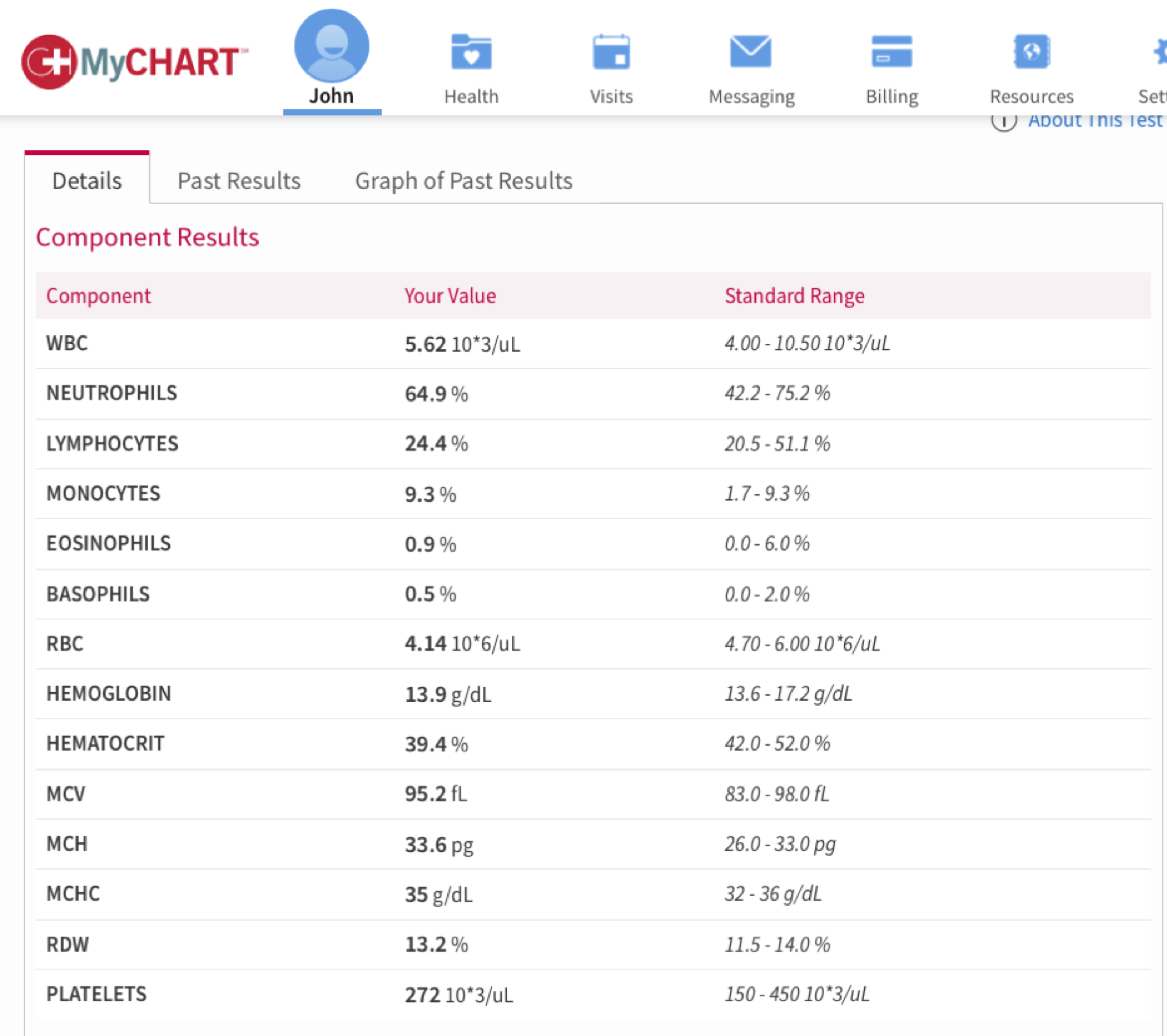
FIGURE 1.1: A typical report of a medical test makes finding deviations from the normal range difficult.
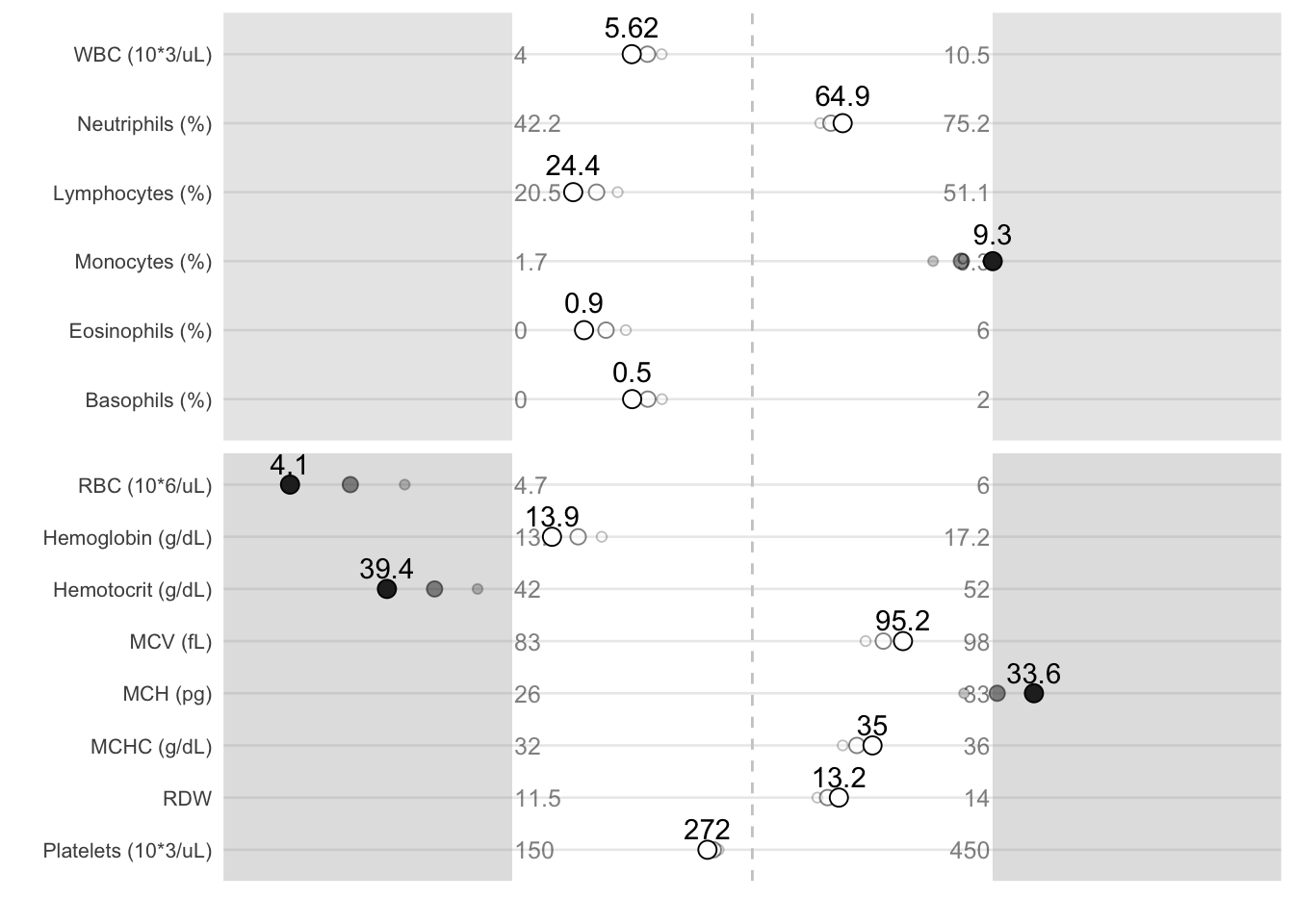
FIGURE 1.2: A visualization of the same results makes the deviations pop out.
1.2 Seeing more than summary statistics
The easy availability of sophisticated machine learning and statistical models makes algorithmic interpretation of data tempting. However, such interpretations can mislead, with similar outcomes produced by very different underlying data.
Figure 1.3 shows four distinct sets of data. The differences are obvious when graphed. One might expect that the typical summary statistics–mean, standard deviation, and correlation–would show equally stark differences. Table ?? shows this is not the case. Each data set has the same summary statistics.
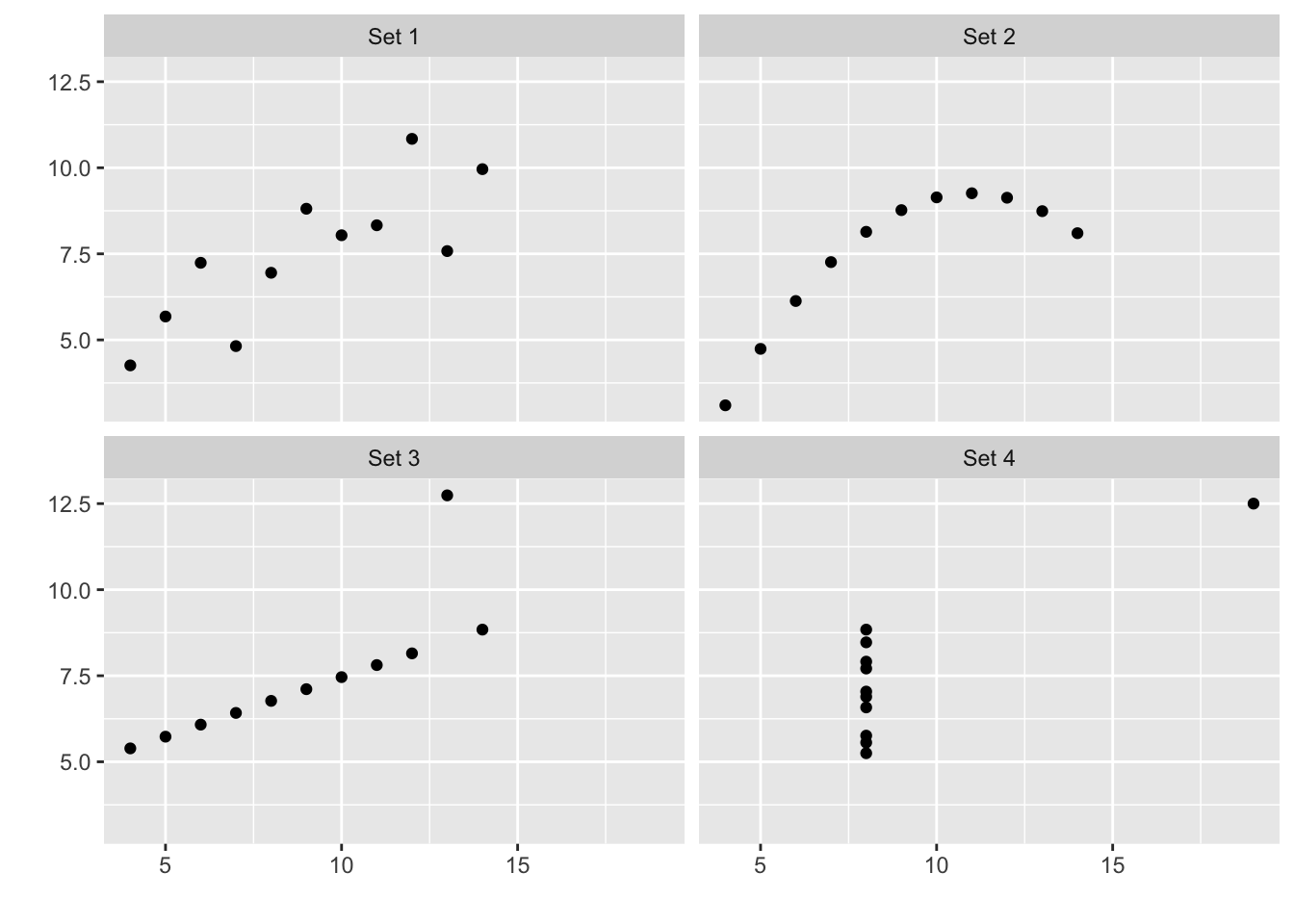
FIGURE 1.3: The Anscombe quartet and the limits of summary statistics.
| set | mean.y | sd.y | cor |
|---|---|---|---|
| Set 1 | 7.501 | 2.032 | 0.8164 |
| Set 2 | 7.501 | 2.032 | 0.8162 |
| Set 3 | 7.500 | 2.030 | 0.8163 |
| Set 4 | 7.501 | 2.031 | 0.8165 |
1.3 Purposes and audiences of visualizations
What makes a “good” visualization depend on whether it is taylored to its purpose and its intended audience. Generally graphs can serve three general purposes–explore, inform, and engage (Gelman and Unwin 2013a)–and understanding what purpose the graph serves can help ensure the graph succedes. The purpose of the graph tends to depend on the audience, which can range from yourself, peers, scientists and engineers, managers, and the public. An extremely effective graph that you might use explore a dataset might fail to support peer in doing the same and might be completely inappropriate for presenting results to managers.
Explore: the answer is unknown and audience is likely yourself and peers involved in the research.
Inform: the answer is known and the audience is likely a broader audience of scientists, engineers, or manager not direclty involved in the research.
Engage: the answer is known and must be communicated in an entertaining way to those who may might neet to be drawn into reading the graph and may not be familiar with conventions of scientific visualization, such as box plots.
1.4 What question to answer?
Triadic perspective that links three distinct elements: 1. the person and their questions 2. the underlying data and its meaning 3. the graphical representation
This triadic perspective places equal emphasis on the analytics and processing of data and the visual representation that must be tailored to the motivation, needs and capacity of the people viewing the graph.
This requires: 1. Abstracting and aggregating (properties of the data) to address the intersts of the audience.11
matching types of graphs (visual representations) to types of questions (properties of the data)
matching types of graphs (visual representations) to the audience (properties of people, their interests, and experience)
1.5 Storytelling with graphics
- High-level principles for communication, such as “Show don’t tell”
- Role of annotation in going beyond the data: direct attention and explain, as in Table 3.1.
Based on https://www.rdocumentation.org/packages/HistData/versions/0.8-4/topics/Minard
1.6 Data sources
This book uses data from the following sources:
Work and life activity: American Time Use Survey (ATUS) https://www.bls.gov/tus/ https://cran.r-project.org/web/packages/atus/atus.pdf
O*NET occupational information: knowledge, skills, abilties, task composition https://www.onetonline.org
Accident data: Occupational injury, motor vehicle crashes Babynames Sleep data Healthcare: Taste: Wine, chocolate
https://www.data.gov Consumer complaint database, NTSB accident database
https://flowingdata.com/category/projects/data-underload/
R packages: HistData, babynames
Yao about data and web scraping and the package
## Read data from website
# sports <- read_tsv("https://github.com/halhen/viz-pub/raw/master/sports-time-of-day/activity.tsv")
## Happiness
happiness.df = read.csv("data/world-happiness-report/2017.csv")
highlight.df = happiness.df %>% filter(
Economy..GDP.per.Capita.>1.75|
Happiness.Score>7.4|
(Happiness.Score>5&Economy..GDP.per.Capita.<.5)|
(Happiness.Score>6&Economy..GDP.per.Capita.<1)|
Country=="United States")
ggplot(happiness.df, aes(Economy..GDP.per.Capita., Happiness.Score)) +
geom_point(colour = "grey25") +
geom_point(data = highlight.df, color = "orange")+
geom_text_repel(data = highlight.df, aes(label = Country))+
labs(title = "Money doesn't buy happiness, but it helps",
subtitle = "Source: https://www.kaggle.com/unsdsn/world-happiness 2017",
y = "Happiness", x = "Per capita GDP")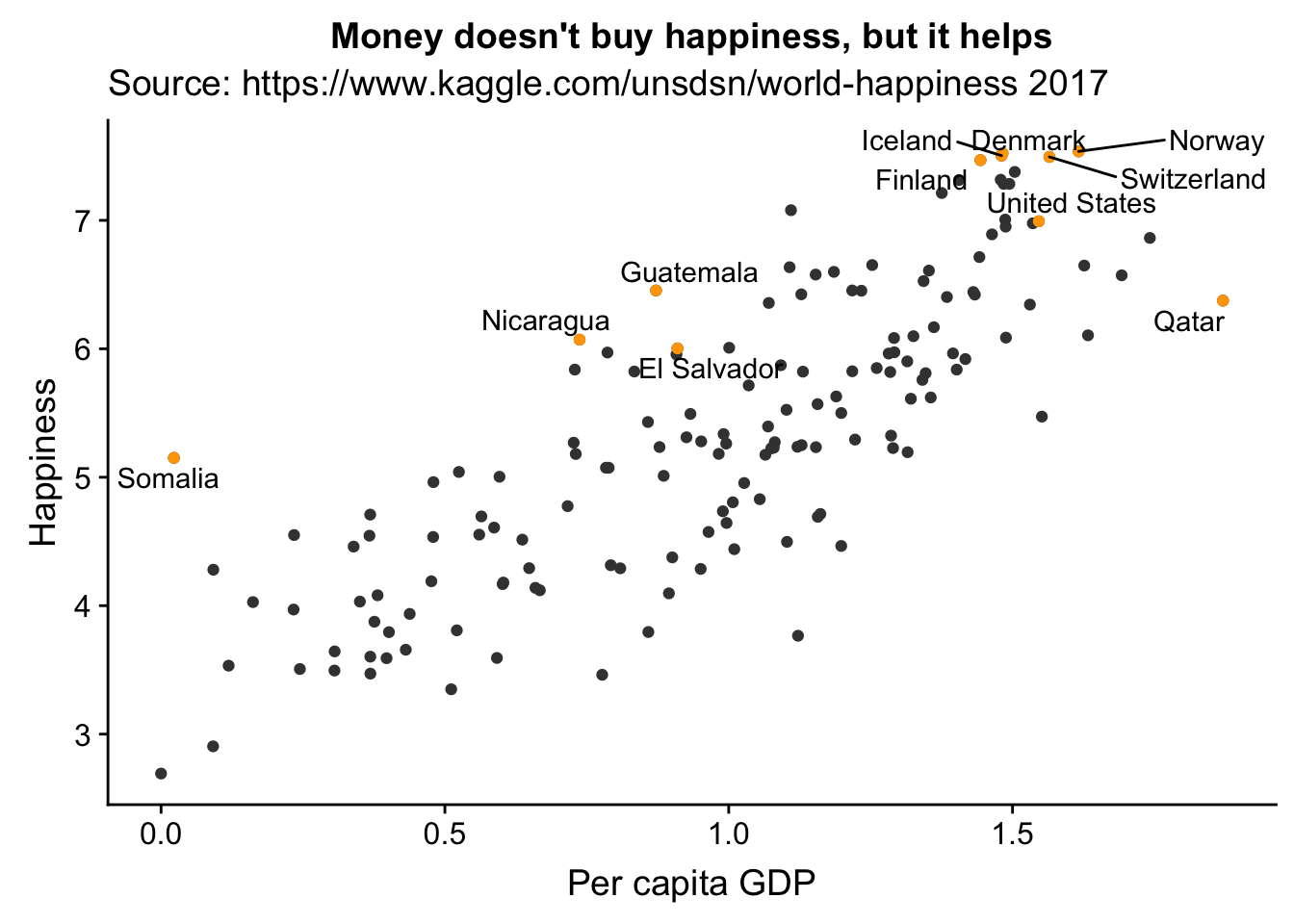
## Chocolate
# chocolate.df = read.csv("flavors_of_cacao.csv")
# chocolate.df$Cocoa.Percent = as.numeric(chocolate.df$Cocoa.Percent)
# ggplot(chocolate.df, aes(Cocoa.Percent, Rating)) + geom_point()
## Police
## 2535 observations, Age, gender, how armed, state, threat, body cameraAll factors
police.df = read.csv("data/PoliceKillingsUS.csv")
# Canadian vehicle specifications: http://www.carsp.ca/research/resources/safety-sources/canadian-vehicle-specifications/1.7 Grammar of data manipulation
This book is not about data reduction and data wrangling. The tidyverse provides an intrgrated set of tools for data wrangling http://r4ds.had.co.nz.
Filter, select, mutate summarise
1.8 Grammar of graphics
Data, layers of geometric eleements, map and set aesthetic properties of each layer of geometric element locally or globally Simple example
1.9 Considering cognitive capabilities in graphic design
Capitalizing on power of visual perception Same graph with out without consideration
B References
Gelman, Andrew, and Antony Unwin. 2013a. “Infovis and Statistical Graphics: Different Goals, Different Looks.” Journal of Computational and Graphical Statistics 22 (1): 2–28. https://doi.org/10.1080/10618600.2012.761137.