Chapter 2 Visualization types and principles
Questions guide choice of general graph types Cognitive operations needed to answer questions guide the choice of graphical details The path of attention associated with a sequence of cognitive operations needed to form a coherent story guides the choice of layout and interactive elements
Four general aspects of visual perception and cognition govern how well people interpret graphs:
- Guidance and span of the attentional spotlight
- Sensitivity to grouping and patterns
- Discrimination and judgement of values
- Sensitivity to navigation cohence and narative structure
2.1 Pairing questions and graph types
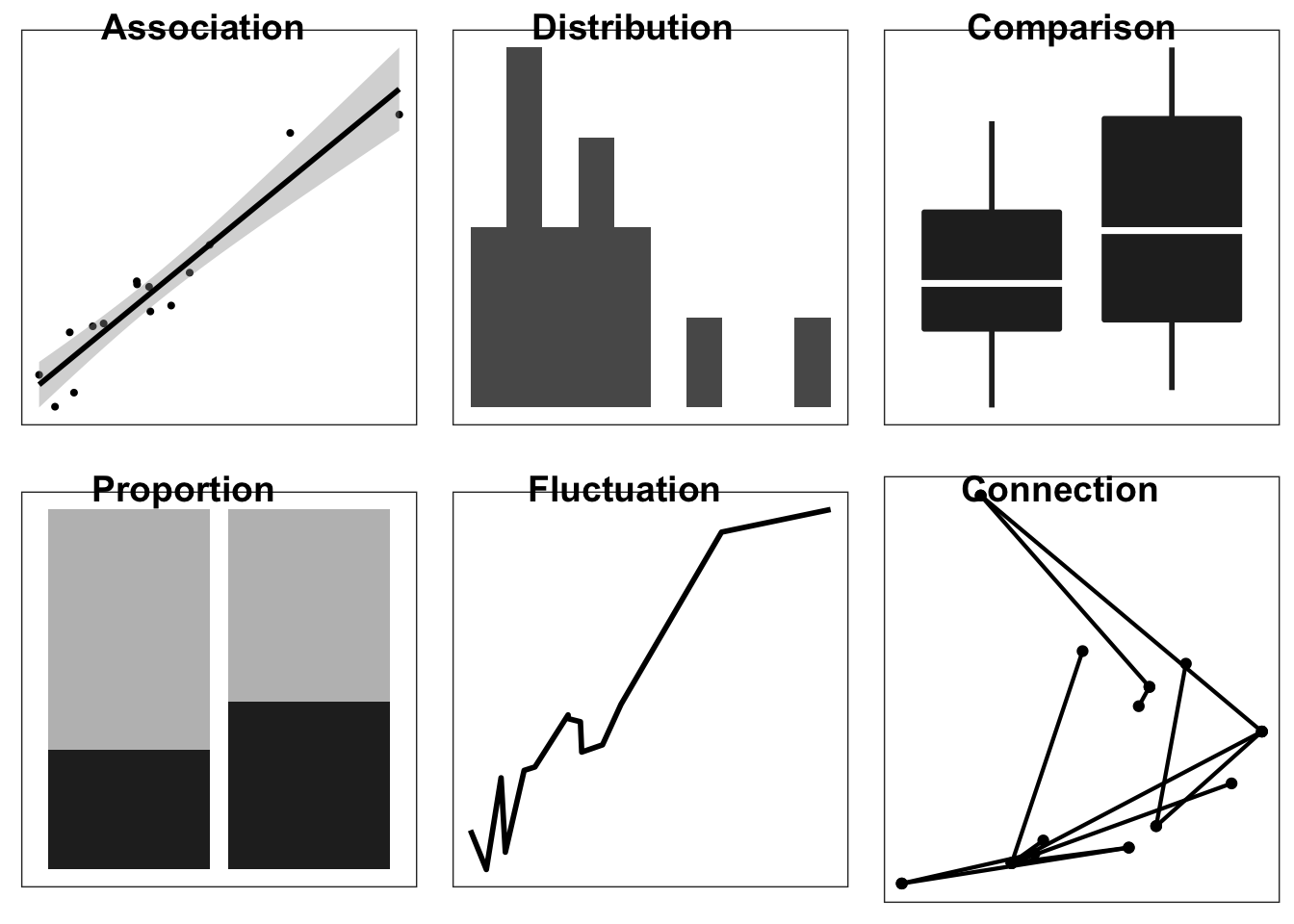
Graphs answer questions about data by showing relationships and making comparisons easier. Before creating a graph it is critical to specify the questions and comparisons of interest. Figure ?? shows common graphs and general questions they might answer. For example, in the upper left is a graph that shows the association between variables. This type of graph answers questions such as “how does X influence Y?”, as in “does increasing the prices of gas reduce the amount of driving?”. A scatter plot shows the strength and nature of this association. Each graph in Figure ?? is suited to a different question:
Graphs answer questions about data by showing relationships and making comparisons easier. Before creating a graph it is critical to specify the questions and comparisons of interest. Table shows common graphs and general questions they might answer. For example, in the upper left is a graph that shows the association between variables. This type of graph answers questions such as how does X influence Y, as in ``does increasing the prices of gas reduce the amount of driving?’’. A scatter plot shows the strength and nature of this association.
- Association: What influences an outcome?
- Distribution: What is the spread of the observations?
- Comparision: How does one condition differ from another?
- Proportion: What is the size of the components that make up the whole?
- Fluctuation: How does the do observations vary over time?
- Connection: How are the observations connnected over a map or network?
Combinations of questions, such as changes in distribution or proportion over time
Questions in terms of patterns vs precision
Graph type and familiarity, pie charts Scatter plot to 2-density, comparison to ranking, dotplot to violin or boxplot.
Graph types and volume of data.
More data requires abstraction. Some plots scale well others do not, overplotting one example of scaling challenges with increasingly large data.
More data points and more variables (e.g., time sequences, categories), organize chapters to move from few points and few variables to many (e.g., histogram to small multiple, to heatmap)
Types of data sets: Number of observations (independent, sequential) Number variables (nominal, ordinal, interval)
~50 observations and 5 nominal and 7 interval variables (mtcars, IIHS vehicle fatalities) ~50 observations and 1 nominal and 4 interval variables (iris) ~200 observations and 2 nominal and interval variables (10) (belts) ~50,000 observations an 10 nominal and interval variables (diamonds)
The examples for each type of graphs represent one of many possible representations. For example, the stacked bar chart addresses questions of proportion, but so can pie charts and 3-D pie charts. How do you choose between these alternatives? One consideration is to select display dimensions that make it easy for people to make comparisons needed to answer the questions—identify effective mapping between data and display dimensions—which we turn to in the following section.
2.2 Percpetual processes to be supported: Comparison, Detection, Pattern identification
Attentional span Visual WM limits Preattentive cues Compatability Conventions and familiarity
2.2.1 Read and judge values
Differences between conditions, Compare to zero? Perceptual sensitivity Proximity compatibility principle (enable relative rather than absolute comparisons with reference lines and data ordering)
cyl_mtcars.df = mtcars %>% mutate(cyl = as.factor(cyl)) %>%
group_by(cyl) %>%
summarise(m.mpg = mean(mpg))
ggplot(cyl_mtcars.df, aes(cyl, m.mpg)) +
geom_col(fill = "grey70") +
geom_text(aes(label = round(m.mpg, 1)), vjust = 1.5)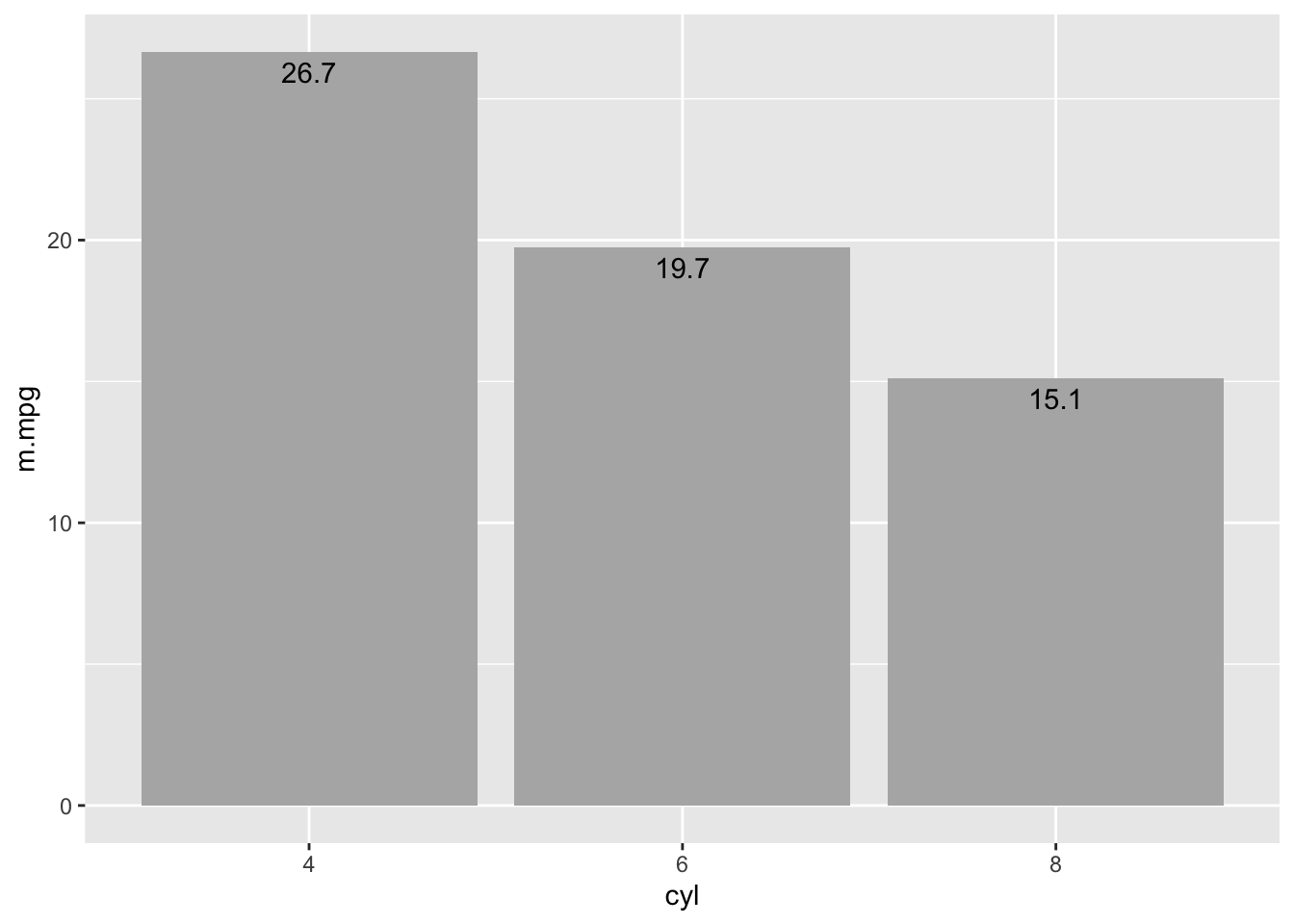
2.2.2 Compare values
2.2.3 Detect and select
Outliers, deviations from assumptions Popout effects TODO Create figure to show cost of conjunctive search and benefit of redundant coding
2.2.4 Identify groups and patterns
Associations, interactions, and changes over time Gestalt principles
Preattentive processing
TODO Create figure to show relative benefit of shape, intensity color for grouping
Grouping and gestalt Similarity Continuity Connection Proximity Enclosure Closure
TODO Figure ground showing data and summary vs summary and data
2.2.5 Narrative structure and sequence
Storytelling and visual momentum
2.3 Principles from general to specific
(Tufte 1983), (Munzner 2014, @Gelman2013a)
ten guidelines (Kelleher and Wagener 2011)
Guidelines for HF publications (Gillan et al. 1998)
Comprehensive book on visualization (Ware 2013)
Effort to separate and effort to integrate–focussed and selective attention
2.3.1 Identify audience, story, and key relationships (Few)
2.3.2 Focus attention and organize reading
Group Prioritize Provide context Sequence
Be consistent, every difference should tell
2.3.3 Annotate to show cause and explain why
2.3.4 Concrete details engage and are memorable
Connect to the world
2.3.5 Enable comparisons and put data in context
(Tufte) Scatter plot: Data points with linear and loess models Category plot: Boxplot with individual data points Time series: Small multiples with grand mean
Estimation errors and effort proportional to the absolute difference from common baseline: reference lines provide a local baseline. TODO Show tall bars with mean reference line
2.3.6 Map types of variables to graph features
Mapping data to graph features (Cleveland and McGill 1985)
For the purposes of display design, three different data types guide the choice of display dimensions: interval, ordinal, and nominal (Cleveland and McGill 1985). Interval data include real or integer numbers (e.g., height and weight), ordinal data are categories that have a meaningful order (e.g., compact, mid-size, and full-size cars), and nominal data are categories that have no order (e.g., male, female). Each data type can be represented with one of several graph dimensions, such as color or position, but certain mapping support more accurate judgments.
Size of circle: map to radius or the area TODO create plot to show map to radius and area
TODO show good and bad mappings
color (Silva, Sousa Santos, and Madeira 2011)
data = read.csv('data/DataAestheticMapping.csv')
data$Type = factor(data$Type, levels=c("Interval", "Ordinal", "Nominal"))
ggplot(data, aes(Type, reorder(Rank, -Rank), group = Aesthetic)) +
geom_line(alpha = .4, size = 2.5) +
geom_text(aes(label = Aesthetic), size = 5) +
ylab("Rank") + xlab("Data type") +
theme_bw()
FIGURE 2.1: Aesthetic mapping.
%TODO figure for mapping types of data and graph dimensions (Cleveland and McGill 1985)
Figure XX shows seven ways to code these data (Cleveland and McGill 1985). For all three types of data, position, such as the horizontal or vertical placement of a point in a graph, support the most precise judgments. The other ways of coding information depend on the type of data: hue is a poor choice for interval data, but a good choice for nominal data, as is shape. Because shape and color have no natural mapping to magnitude, they are a poor choice for interval and ordinal data. Magnitude is best represented by position on a common scale, followed by position on an unaligned scale, length and then angle, followed by size (Munzner 2014, @Cleveland1985). Because size and angles are relatively hard to judge, pie charts are not a good way to represent proportions.
Limits of absolute judgment underlie the effectiveness of coding data with various display dimensions. Coding nominal data with more than seven hues will exceed people’s ability and so they would not be able to reliably link lines on a graph to categories. Data presented on aligned scales, such as the bottom category in a stacked bar chart, can be judged very precisely, but the limits of absolute judgment make interpreting the upper categories more difficult. This means that the bottom category of a stacked bar chart should be chosen carefully. Generally, avoid placing data on unaligned scales. Instead, support relative judgments based on a common scale. The circular format of pie charts means that there are no aligned scales and is another reason why they are not as effective as stacked bar charts.
Because visualization involves multiple conceptual dimensions, a natural choice is to use three-dimensional Euclidian space. However, three-dimensional figures make accurate comparisons difficult due the ambiguity of rendering three dimensions on a two dimensional plane. Of all the ways to represent a quantity, the volume of a three-dimensional object leads to the most inaccurate judgments (Munzner 2014).
Another important conceptual dimension is time. Time, like space, is compatibly mapped to display dimension of position, often advancing from left (past) to right (future). Time can also be directly mapped to display time via animation. Animated graphs can be compelling, but they require working memory to track objects across the display and so severely limit the number of data points that can be compared. Interactive visualization described in Chapter 10 can give control with a slider and avoids this limit to some degree.
2.3.7 Ensure proximity compatibility
Proximity compatibility and legend: link to line, orientate to match orientation in graph, sequence to match sequence in graph
Visual attention must sometimes do a lot of work, traveling from place to place on the graph, and this effort can hinder graph interpretation. Hence, it is important to construct graphs so things that need to be compared (or integrated) are either close together in space or can be easily linked perceptually by a common visual code. This, of course, is a feature for the proximity compatibility principle (A3) and can apply to keeping legends close to the lines that they identify, rather than in remote captions or boxes. Similarly, when the slopes and intercepts of two lines need to be compared, keep them on the same panel of a graph rather than on separate panels. The problems of low proximity will be magnified as the graphs contain more information—more lines. Similarly, in a box plot with many categories people will be able to compare categories that are close to each other more precisely than those that are separated. You should order categories so that those to be compared are closest.
Proximity goes beyond physical distance. A line linking points on a timeline can enhance proximity as can color and shape. Lines and color can be effective ways of making groups of points in a network diagram ``closer’’, and easier to interpret as a group. Objects with identical colors tend to be associated together, even when they are spatially separated. Furthermore a unique color tends to stand out. It is also the case that space is compatibly mapped to space, so that visualization of geographic areas is best accomplished when the dimensions of rendered space correspond to the dimensions of displayed space–a map.
As with its application to other display designs, the proximity compatibility principle means that the visual proximity of elements of the graph need to correspond to the mental proximity needed to interpret this information. For graphs, this means the questions and comparisons the graph is intended to address should specify what is ``close’’ in the graph.
2.3.8 Legibility and consistency
As with other types of displays, issues of legibility are again relevant. However, in addition to making lines and labels large enough to be readable, a second critical point relates to discriminability (P9). Too often, lines that have very different meanings are distinguished only by points that are highly confusable, as in the graph on the left of Figure XX. Here incorporating redundant coding of differences can be quite helpful. In modern graphics packages, color is often used to discriminate lines, but it is essential to use color coding redundantly with another salient cue. Why? As we noted in Chapter 4, not all viewers have good color vision, and a non-redundant colored graph printed from a black and white printer or photocopied may be useless.
2.3.9 Maximize data/ink ratio
(Tufte) * Maximize data to create rich representation, minimize extraneous non-data elements
- Minimize non-data elements: bar charts rather than 3-D pie
Annotate to integrate interpretation and data
Simplify to amplify content
Simplify content to amplify point
2.3.10 Manage clutter with grouping and layering
- Match data type to appropriate aesthetics (Cleveland) Only position good for all data types: Focus on 2d-plane and relative judgments Consider data type: size better than color for interval data
Graphs can easily become cluttered by presenting more lines and marks than the actual information they convey. As we know, clutter can be counterproductive , and this has led some to argue that the data-ink ratio should always be maximized (Tufte 1983); that is, the greatest amount of data should be presented with the smallest amount of ink. While adhering to this guideline is a valuable safeguard against the excessive ink of “chart junk” graphs, such as those that unnecessarily put a 2-D graph into 3-D perspective, the guideline of minimizing ink can however be counterproductive if carried too far. Thus, for example, the ``minimalist’’ graph in center of Figure X, which maximizes data-ink ratio, gains little by its decluttering and loses a lot in its representation of the trend, compared to the line graph on the right Figure XX. The line graph contains an emergent feature—slope—which is not visible in the dot graph. The latter is also much more vulnerable to the conditions of poor viewing (or the misinterpretation caused by the dead bug on the page!).
%Figure 21. Space shuttle launches, temperature and O-ring damage. %TODO I love the example, but A more elaborated caption is needed to direct reader’s attention to the problem.
In some cases, the poor data to ink ratio and prevalence of chart junk might create engaging graphics, other times it can be annoying, but in presenting engineering data it can undermine the quality of life and death decisions. Figure 20 shows the graphic used to support the launch decision associated with the disastrous flight of the Space Shuttle Challenger the data presented in this way makes it difficult to assess the effect of temperature on O-ring damage, which may have encouraged the managers to launch in cold weather (Tufte 1997).
Figure X shows that you can increase the data-to-ink ratio by reducing the ``ink’’ devoted to non-data elements. Another way to increase the data-to-ink ratio is to include more data. More data can take the form of reference lines and multiple small graphs, as in Figure XX. More data can also take the form of directly plotting the raw data rather than summary data.
Figure 2.2 shows an extreme version, in which each data point represents one of approximately 693,000 trips reported in the 2009 travel survey XXcite FHWA2011. The horizontal axis indicates the duration and the vertical axis shows distance of each trip. The diagonal lines of constant speed place these data in context by showing very slow trips—those under the 3mph line—and very fast trips—those over the 90mph line. Histograms at the top and side show the distribution of trip duration and distance. The faint vertical and horizontal lines show the mean duration and distance. Like other visualizations that include the raw data, this visualization shows what is behind the summary statistics, such as mean trip distance and duration.
Showing the underlying data has the benefit of providing a more complete representation, but it can also overwhelm people. Data can create clutter. One way to minimize clutter is by grouping and layering the data. In the case of Figure 2.2 this means making the individual data points small and faint.
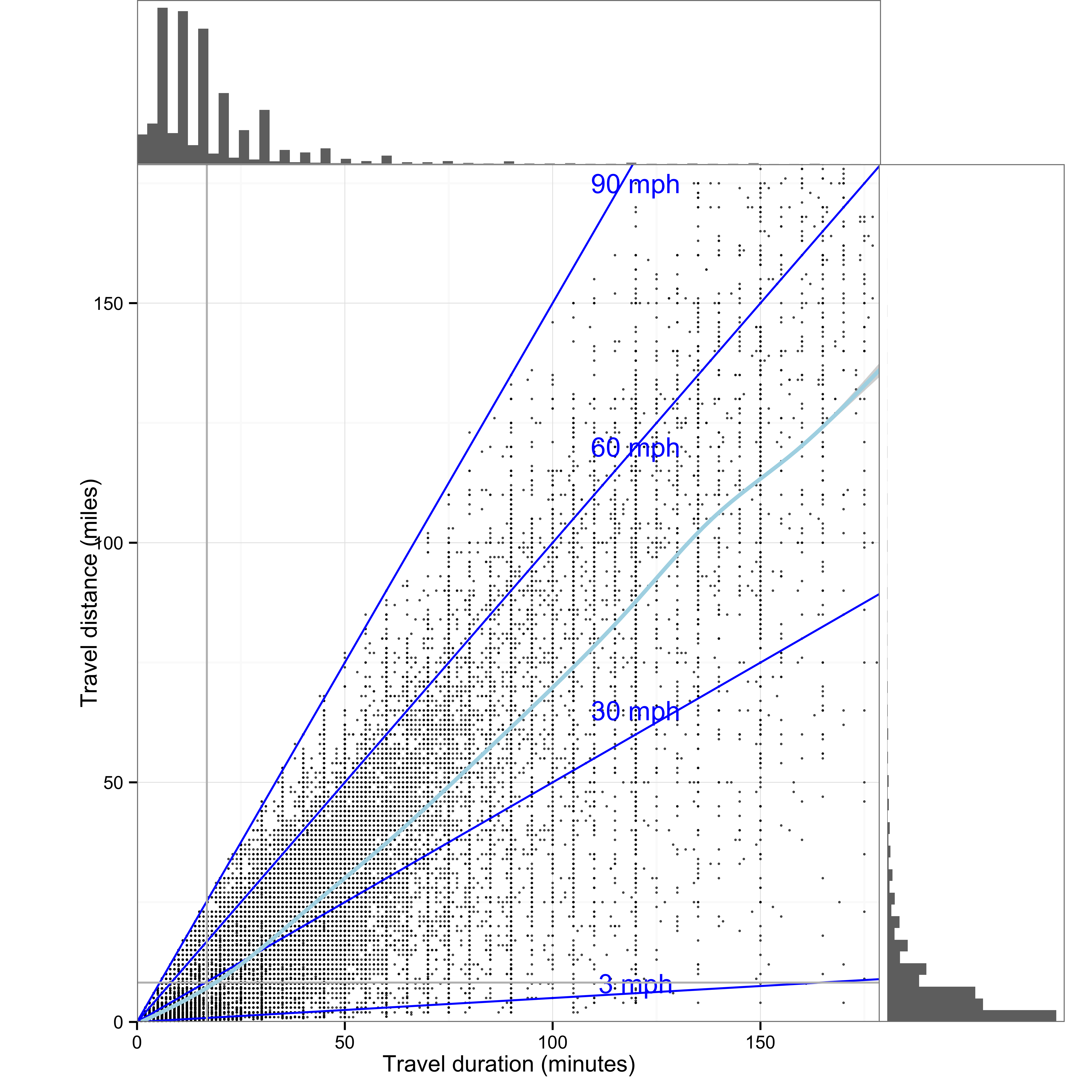
FIGURE 2.2: An example of extreme data-to-ink with over 693,000 data points
2.4 Overview of examples
Simple, few variables, few observations and single graphical element to and complex, many observations to combitions of graphical elements
B References
Cleveland, W. S., and R. McGill. 1985. “Graphical perception and graphical methods for analyzing scientific data.” Science 229 (4716): 828–33. uuid/B8170B5D-424C-4EC6-9939-0836A9777112.
Gillan, D. J., C. D. Wickens, J. G. Hollands, and C. M. Carswell. 1998. “Guidelines for presenting quantitative data in HFES publications.” Human Factors 40 (1). SAGE Publications: 28–41. https://doi.org/10.1518/001872098779480640.
Kelleher, C., and T. Wagener. 2011. “Ten guidelines for effective data visualization in scientific publications.” Environmental Modelling and Software 26 (6). Elsevier Ltd: 822–27. https://doi.org/10.1016/j.envsoft.2010.12.006.
Munzner, T. 2014. Visualization Analysis and Design. Boca Raton, FL: CRC Press.
Silva, S., B. Sousa Santos, and J. Madeira. 2011. “Using color in visualization: A survey.” Computers and Graphics 35 (2). Elsevier: 320–33. https://doi.org/10.1016/j.cag.2010.11.015.
Tufte, E. R. 1983. The Visual Display of Quantitative Information. Cheshire, CT: Graphics Press.
Tufte, E. 1997. Visual Explanations: Images and Quantities, Evidence and Narrative. Cheshire, CT: Graphics Press.
Ware, C. 2013. Information Visualization: Perception for design. Boston, MA: Elsivier.